Data Science Job Postings with Salaries (2025)
by L. Mark Coty
This dataset contains data science job postings with salary information, collected and processed in 2025. It is designed for projects in salary prediction, job market analytics, and machine learning research.
GitHub repository here. Run the notebook.
Purpose:As a data engineer, I was immediately interested when I encountered this recent dataset containing data gathered from job postings for Data Scientists, Machine Learning Engineers, and others.Upon closer inspection, there seemed to be enough data to ask and possibly answer the questions:1. Which job titles carried the highest salary offers?2. Which factors (location, skills required, company size, etc.) had the most effect on salary sizes?
Overview:I began with a dataset containing 13 columns and 944 rows, each representing a job offer. By the time all the data had been cleaned and regularized, there were only 10 columns remaining, one of them being the target, "salary."The GitHub repository containing all of the work can be found here.
The Content and Nature of the Data:
The columns in the dataset and their types are as follows:
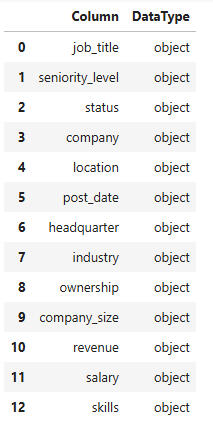
As described in the ReadMe, we converted company-size, revenue, salary, and skills into numerical columns. Post_date was dropped, since it contained 2025 as its only value.
Explanation of columns and values:

After the cleaning as described in the ReadMe, we have no null values:
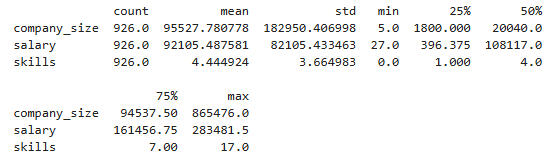
The summary stats of the numerical columns are shown here:
To Visualize the Categorical Data, We Can Examine Their Bar Graphs:
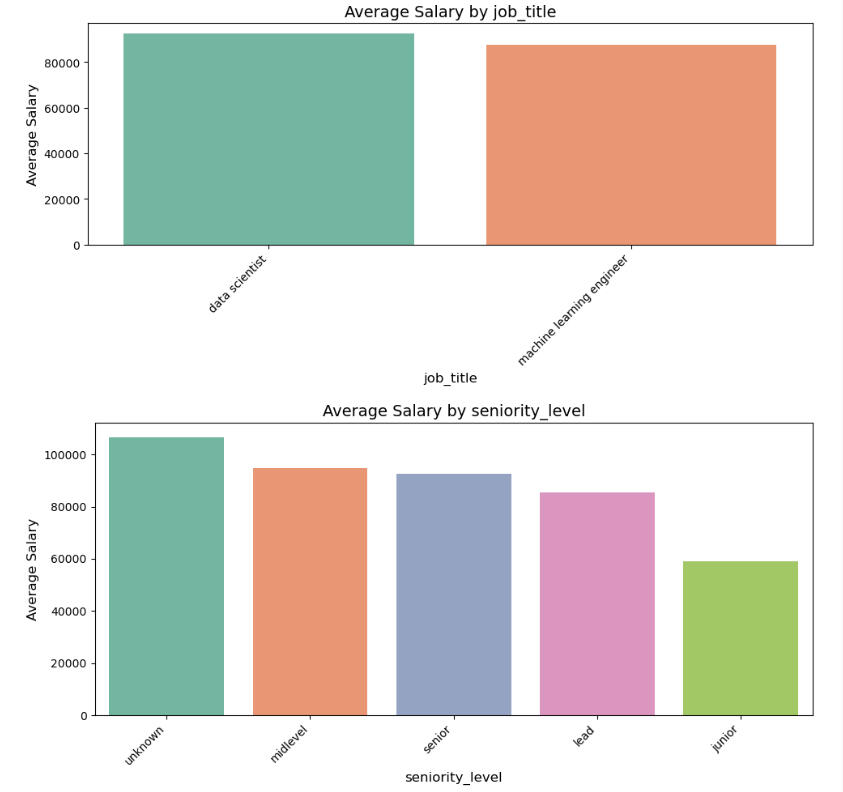
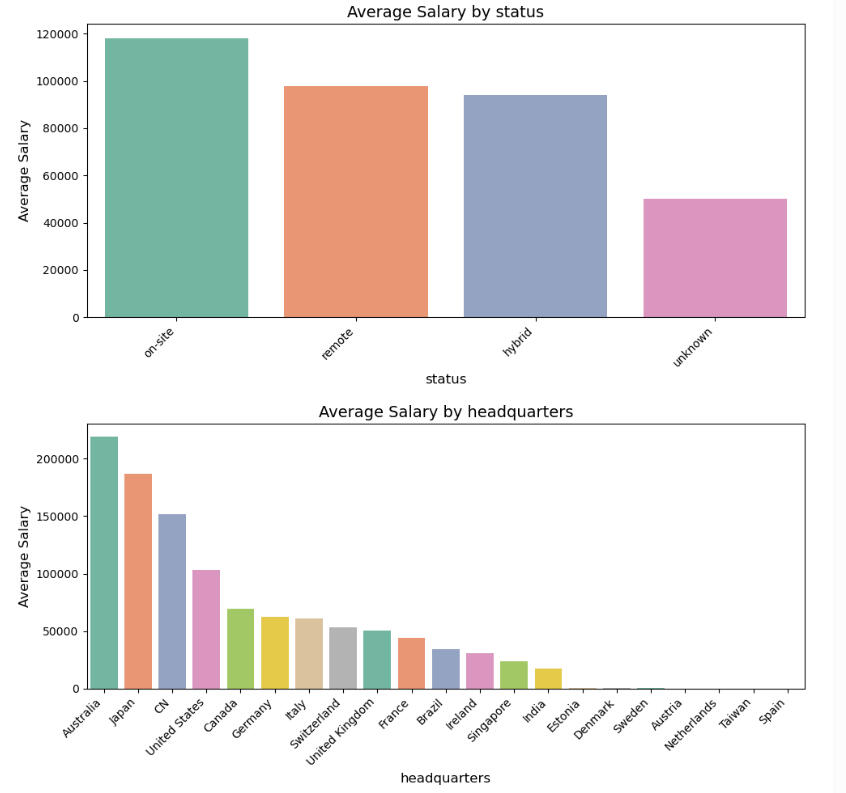
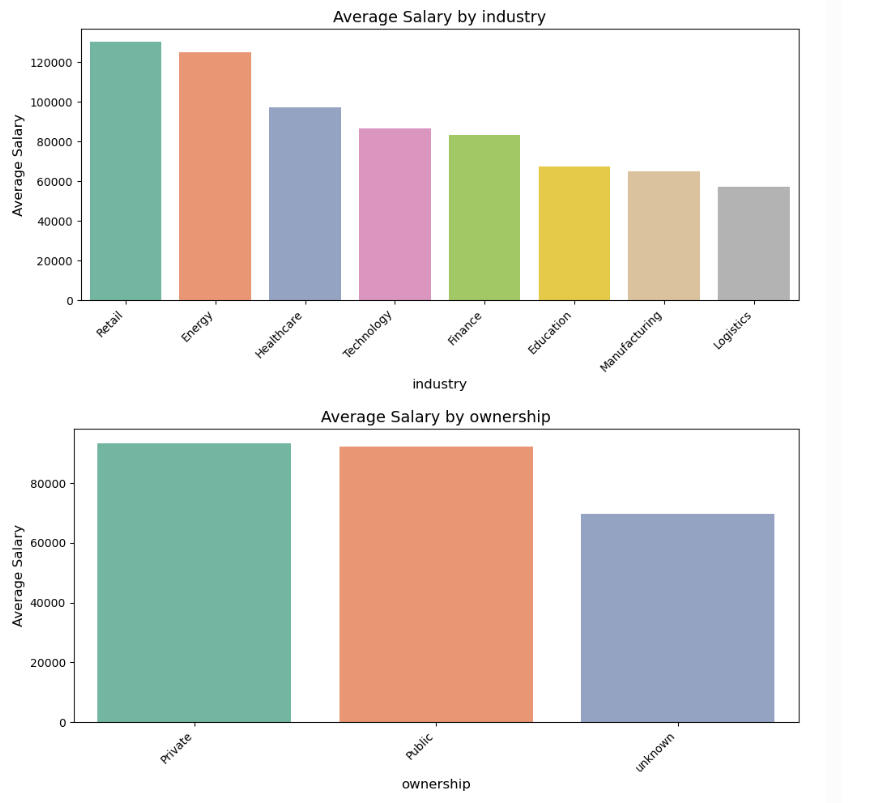
Observations from the above graphs:
Salaries are nearly equal for the two job titles.
Salaries are surprisingly similar for the known levels. The larger figure for "Unknown" must indicate a mix of higher-paying jobs. Maybe there are enough to explain why "Midlevel" and "Senior" and "Lead" are so close together.
The fact that On-site jobs pay more than Remote or Hybrid is not surprising.
The top three countries being Australia, Japan, and China seems significant.
In Industry, the fact that Retail, Energy, and Healthcare surpass Tech is worth noting.
The virtual tie between Private and Public companies is also of note.
Let's look at the pairplots, coefficients, and trend lines for our numeric columns:
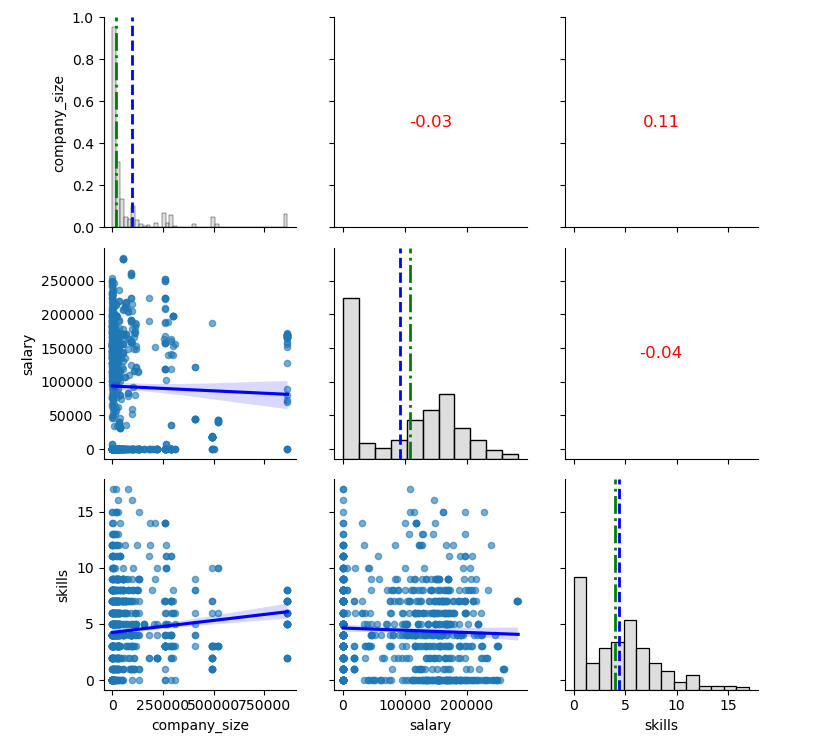
A few observations on the above graphs:
- The shapes of the histograms are unsurprising:
- Company size is left-skewed, with the mean at about half the median.
- Salary has only a slight right skew, due to the large bar at the left balancing the higher salary counts.
- Skills is a smilar shape, with what would be a right skew balanced by the large column at the left end. Median and mean are very close.
- The correlations are all negligible. It is hard not to comment, though, on the (very) slight negative correlation of salary over company size.
Now we will use a binary classification approach to see which features best predict "High Salary" (over $100K). We'll hold out 20% of the data and employ Logistic Regression, Random Forest, and XGBoost models using all features.
The results of employing these classifiers are summarized below:

Observation on the above values:The Random Forest model performed the best in all metrics, with a fairly impressive 78% accuracy and 81% recall.
Hypothesis Testing:
We'll now perform a 2-sample T-test to see how salaries for Data Scientists and ML Engineers compare:

Let's test whether the distributions of the salaries are significantly different:
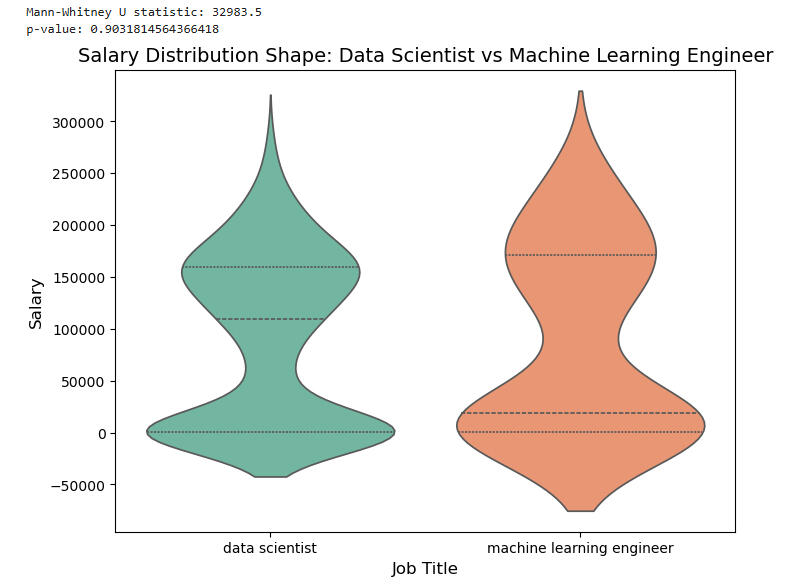
As we can see from the plots and from the huge p-value, there is no significant difference in the distributions of the salaries between the two job titles.However, there is one feature of the plots that is startling: the much higher median for the Data Scientist jobs.Let's compare medians:

Let's try removing the lowest 10% of salaries from our already-small MLE sample and run the Mann Whitney test again:
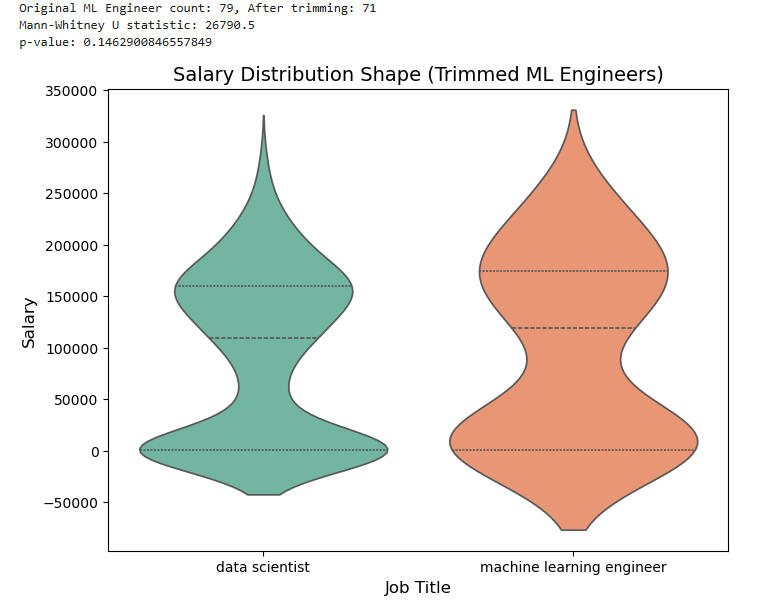
Now the situation has changed: The quartiles for both categories (including the medians) are nearly identical.
Conclusions:- The means of the salaries posted for Data Scientist and Machine Learning Engineer are nearly identical.- The medians of the salaries, in our dataset, were widely disparate.- By doing a little data cleaning, removing the bottom 10% of MLE salaries, we were able to show that the medians and other quartiles are nearly identical. This cleaning was justified, since some of the salaries for the MLE column were absurdly low, as low as $55!